Fine-Tuning BERT for text-classification in Pytorch
BERT is a state-of-the-art model by Google that came in 2019. In this blog, I will go step by step to finetune the BERT model for movie reviews classification(i.e positive or negative ). Here, I will be using the Pytorch framework for the coding perspective.
BERT is built on top of the transformer (explained in paper Attention is all you Need). If you want to know how the transformer work, you can check out my blog on the Transformer- Attention is all you Need
Before digging into the code let’s first understand how the model works.
Input text sentences would first be tokenized into words, then the special tokens ( [CLS], [SEP], ##token) will be added to the sequence of words.
Then, the sequence of tokens would be converted to the numeric ids from the embedding table which is a component we get with the trained model. The BERT tokenizer does all these steps in one go.

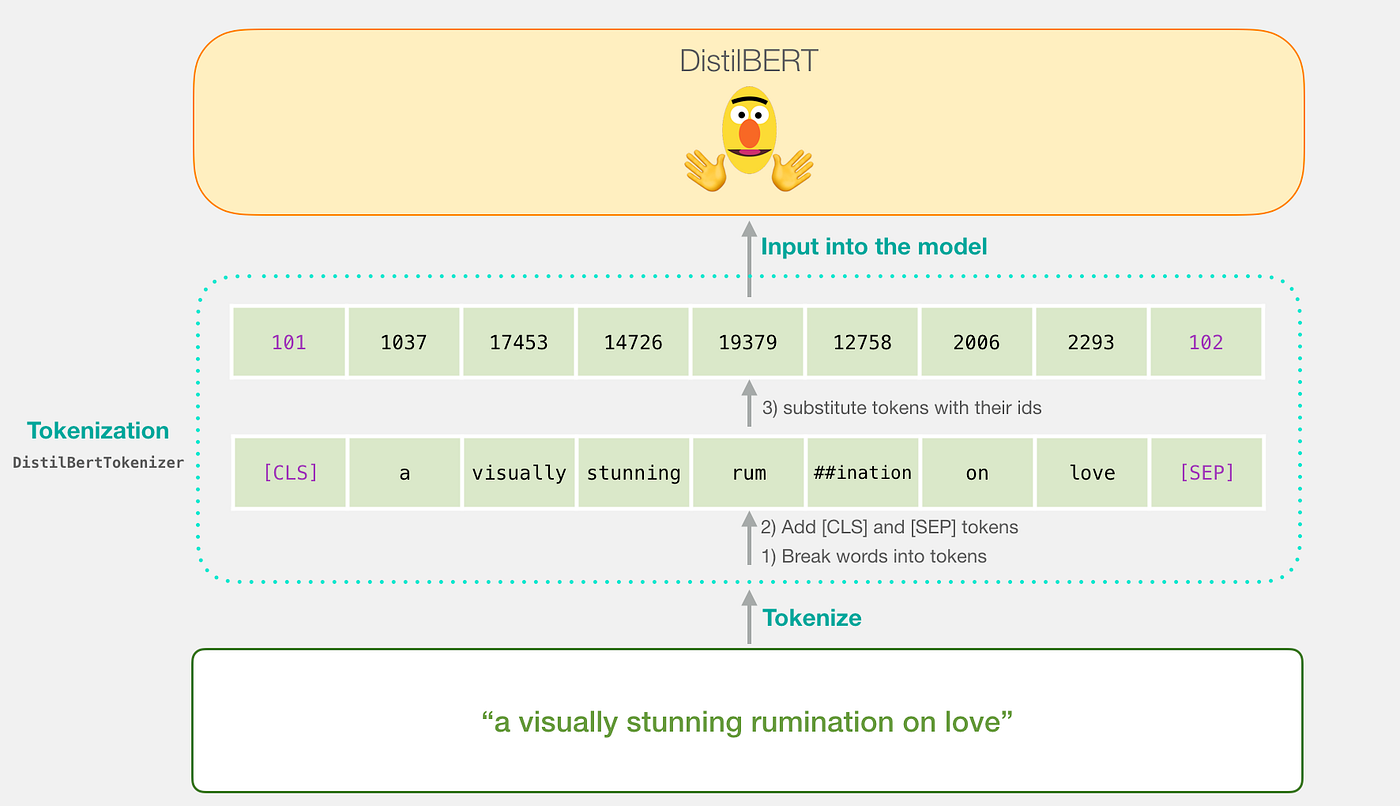
Finally, these token ids will be input to the model and the output will be the vector of 768 dimensions for each token of a given length. For the classification task, all the vectors except the one which came from the [CLS] token would be ignored as only that 786 dimension vector will be used to perform the classification task by applying logistic regression or by adding one dense linear layer followed by the softmax function

THE CODE
First, we need to install the transformers module by Hugging face in our system to make use of all the transformers model by using a simple command in the command prompt.
pip install transformers
Then, import all the packages and modules
In line 3, the transformers module is imported from where we will use pre-trained BERT.
Prepare Dataset
Now we need to prepare a dataset to finetune BERT.
This is a standard method to make a dataset in PyTorch. First, we create a class inherited from the torch Dataset module. Then, In this class, we make the __getitem__ method where the main code will be implemented to prepare a dataset.
In line 2, the input is taken as Bert tokenizer (which we initialize later) which is used to tokenize the input sentence and max length of an input training sequence to make the input of the same length.
In line 5, Dataset is loaded from GitHub, which consists of 2000 movie reviews with labels and converted to pandas dataframe.
In line 13, __getitem__ method is initialized which takes an index as a parameter.
In line 17, BERT tokenizer.encode_plus method takes input as a pair of text sequence with additional parameters like max_length (Controls the maximum length to be used by one of the truncation/padding parameters.), pad_to_max_length (Pad to a maximum length specified with the argument max_length ) and return_attention_mask: bool (This argument indicates to the model which tokens should be attended to, and which should not).
tokenizer.encode_plus returns a dictionary containing the encoded tokenized sequence and other additional information such as attention_marks, token_type_id, and this would be an input to the BERT model.
In line 35, from the hugging face library, the pre-trained BERT uncased tokenizer is initialized and then taken as input in dataset class.
BERT MODEL
Now, we have prepared our dataset and it will be a perfect time to create and initialize our BERT model.
In line 4, we have initialized our pre-trained ‘bert-base-uncased’ BERT model from Hugging face library and followed by initializing our linear dense layer for classifying movie reviews.
Here, we use BCEWithLogitsLoss which combines a Sigmoid layer and the BCELoss in one single class because this version is more numerically stable than using a plain Sigmoid followed by a BCELoss.
Train Model
We have prepared the dataset and also we have defined our BERT model. Now, it’s time to train our model.
Also, now we have two situations:
First, we do not retrain our pre-trained BERT and train only the last linear dense layer.
For this, we need to define it as follows :
Second, we train our complete BERT model. For this, we don’t need to do anything initially, model parameters required_grad is set to True.
Finally, we call a function to Finetune our BERT model
Now, training will be started and you can hyper-tune your parameters for optimizer learning rate and the number of epoch to be trained.
