PinnedLuv BansalAdvance RAG- Improve RAG performanceUltimate guide to optimise RAG pipeline from zero to advance- Solving the core challenges of Retrieval-Augmented Generation10 min read·Feb 26, 2024--7--7
PinnedLuv BansalinTowards AIA Complete Guide to RAG and LlamaIndexA comprehensive guide to Retrieval-Augmented Generation (RAG) with LlamaIndex Implementation12 min read·Jan 3, 2024--2--2
PinnedLuv BansalBenchmarking LLMs: How to Evaluate Language Model PerformanceUltimate guide to evaluating LLMs- Covers Key Benchmarks and why specific Benchmarks should be prioritised for different tasks8 min read·Nov 1, 2023--2--2
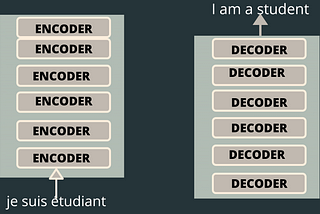
PinnedLuv BansalTransformer — Attention Is All You Need Easily Explained With IllustrationsThe transformer is explained in the paper Attention is All You Need by Google Brain in 2017. This paper came with evolution in the field…9 min read·Sep 17, 2021--2--2
Luv BansalinAI ScienceSpeculative Decoding — Make LLM Inference FasterImprove LLM inference speed by 2–3X without degrading any accuracy6 min read·Apr 8, 2024----
Luv BansalinTowards AILLM Quantisation: Quantise Hugging face Model with GPTQ, AWQ and BitsandbytesUltimate guide to Quantizing LLM — How to Quantize a model with AWQ, GPTQ and Bitsandbytes, push a quantized model on the 🤗 Hub, load an…9 min read·Mar 18, 2024----
Luv BansalMistral 7B: Open source ModelMistral-7B is a SOTA language model with a whopping 7.3 billion parameters outperforms llama2–13b on every metric. It represents a…2 min read·Sep 29, 2023----
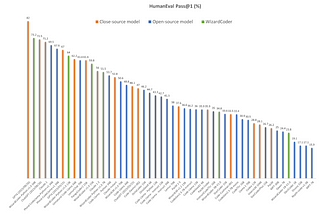
Luv BansalinTowards AIWizardCoder: Why It’s the Best Coding Model Out ThereIn this blog, we will dive into what WizardCoder is and why it stands out as the best coding model in the field. We’ll also explore why its…8 min read·Sep 27, 2023--1--1
Luv BansalGuide Of All Open Sourced Large Language Models(LLMs)A Comprehensive Guide to all Open Source Foundational Large Language Models (LLMs) and Their Comparisons11 min read·Aug 23, 2023----
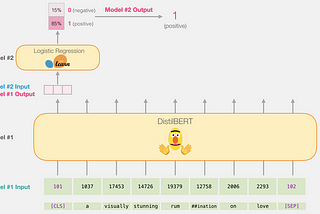
Luv BansalFine-Tuning BERT for text-classification in PytorchBERT is a state-of-the-art model by Google that came in 2019. In this blog, I will go step by step to finetune the BERT model for movie…4 min read·Sep 17, 2021--3--3